
.png) 1 month ago
39
1 month ago
39
Ask Google’s AI video tool to create a film of a time-travelling doctor who flies around in a blue British phone booth and the result, unsurprisingly, resembles Doctor Who.
And if you ask OpenAI’s technology to do the same, a similar thing happens. What’s wrong with that, you may think?
The answer could be one of the biggest issues AI chiefs face as their era-defining technology becomes ever more ubiquitous in our lives.
Google and OpenAI’s generative artificial intelligence is supposed to be just that – generative, meaning it develops novel answers to our questions. Ask it for a time-travelling doctor, you get one that their systems have created. But how much of that output is original?
The problem is working out how much tools like OpenAI’s ChatGPT and its video generator Sora 2, and Google’s Gemini and its video tool Veo3, rely on someone else’s art to come up with their own inventions, and whether using source material from the BBC, for example, is an infringement of the broadcaster’s copyright.
Creative professionals and industries including authors, film directors, artists, musicians and newspaper publishers are demanding compensation for the use of their work to build those models – and for the practice to stop until they have granted permission.
They also argue that their work is being used without compensation in order to build AI tools that create works in direct competition with their own. Some news publishers, including the Financial Times, Condé Nast and Guardian Media Group, publisher of the Guardian, have struck licensing deals with OpenAI.
A key sticking point is the AI giants’ closely – guarded models, which underpin their systems and make it difficult to know just how much their tech relies on other creatives’ work. One firm, however, claims to be able to shine a light on the issue.
The US tech platform Vermillio tracks use of a client’s intellectual property online and claims it is possible to trace, approximately, the percentage to which an AI generated image has drawn on pre-existing copyrighted material.
In research undertaken for the Guardian, Vermillio created a “neural fingerprint” for various pieces of copyrighted work, before asking the AIs to create similar-looking imagery.
For Doctor Who, it entered a prompt into Google’s popular Veo3 tool asking: “Can you create a video of a time travelling doctor who flies around in a blue British phone booth.”
AI Dr Who video matches 82% of Vermillio’s fingerprintThe Doctor Who video matches 80% of Vermillio’s Doctor Who fingerprint, implying that Google’s model has leaned heavily on copyright-protected work to produce its output.
The OpenAI video, taken from YouTube and stamped with the watermark for OpenAI’s Sora tool, was an 87% match, according to Vermillio.
Other examples created by Vermillio for the Guardian use a James Bond neural fingerprint. A Veo3 James Bond video, created with the prompt: “Can you create a famous scene from a James Bond movie?”, had a neural fingerprint match of 16%.
A Sora video, taken from the open web, had a 62% match with Vermillio’s Bond fingerprint, while images of the agent created by Vermillio using ChatGPT and Google’s Gemini model had matches of 28% and 86% respectively from a prompt citing: “A famous MI5 double ‘0’ agent dressed in a tuxedo from a famous spy movie by Ian Fleming”.

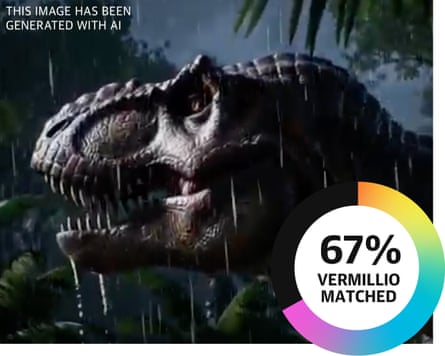
Vermillio’s examples also showed strong matches with Jurassic Park and Frozen for OpenAI and Google models.
Generative AI models, the term for technology that underpins powerful tools such as OpenAI’s ChatGPT chatbot as well as Veo3 and Sora, have to be trained on a vast amount of data in order to generate their responses.
The main source of this information is the open web, which contains a vast array of data from the contents of Wikipedia to YouTube, newspaper articles and online book archives.

Anthropic, a leading AI company, has agreed to pay $1.5bn (£1.1bn) to settle a class-action lawsuit by authors who say the company took pirated copies of their works to train its chatbot. A searchable database of the works used in its models contains a host of well-known names including The Da Vinci Code author Dan Brown, the Labyrinth writer Kate Mosse and the Harry Potter creator JK Rowling.

Kathleen Grace, the chief strategy officer at Vermillio, whose clients include Sony Music and the talent agency WME, said: “We can all win if we just take a beat and figure out a way to share and track content. This would incentivise copyright holders to release more data to AI companies and would give AI companies access to more interesting sets of data. Instead of giving all the money to five AI companies, there would be this amazing ecosystem.”
In the UK the artistic community has launched a vociferous fightback against government proposals to overhaul copyright law in favour of AI companies, who could be allowed to use copyrighted work without seeking permission first; instead, copyright holders would have to signal they wished to “opt out” from the process.
A Google spokesperson said: “We can’t speak to the results of third-party tools, and our generative AI policies and terms of service prohibit the violation of intellectual property rights.”
However, Google-owned YouTube says its terms and conditions allow Google to use creators’ work for making AI models. In September, YouTube said: “We use content uploaded to YouTube to improve the product experience for creators and viewers across YouTube and Google, including through machine learning and AI applications.”
OpenAI said its models train on publicly available data, a process which it claims is consistent with the US legal doctrine of fair use, which allows use of copyrighted work without the owner’s permission in certain circumstances.
The Motion Picture Association trade group has urged OpenAI to take “immediate action” to address copyright issues around the latest version of Sora. The Guardian has seen Sora videos showing copyrighted characters from shows such as SpongeBob SquarePants, South Park, Pokémon and Rick and Morty. OpenAI said it would “work with rights holders to block characters from Sora at their request and respond to takedown requests”.
Beeban Kidron, a crossbench peer in the House of Lords and a leading figure in the fightback against the UK government proposals, said it was “time to stop pretending that the stealing is not taking place”.
“If Doctor Who and 007 can’t be protected then what hope for an artist who works on their own, and does not have the resources or expertise to chase down global companies that take their work, without permission and without paying?”

















































